Claude Code のスキル ccskill-gptimage をオープンソース(MITライセンス)で公開しました。OpenAI の gpt-image-2(ChatGPT Images 2.0)を Claude Code から使って画像を生成できるスキルです。

(本スキルを使って書いてみたもの)
GPT Image2.0 の高い描画力
ccskill シリーズでは、昨年末に画像生成スキルの第一弾として ccskill-nanobanana を公開していました。ドッグフーディングも兼ねて常用していたのですが、今年4月に OpenAI の gpt-image-2(GPT Image 2.0)が発表されました。
画像のクオリティが高いと話題になり、出た当初から Text-to-Image Arena のランキングで首位。こっちもスキル経由で使いたいじゃないかーと思いまして。
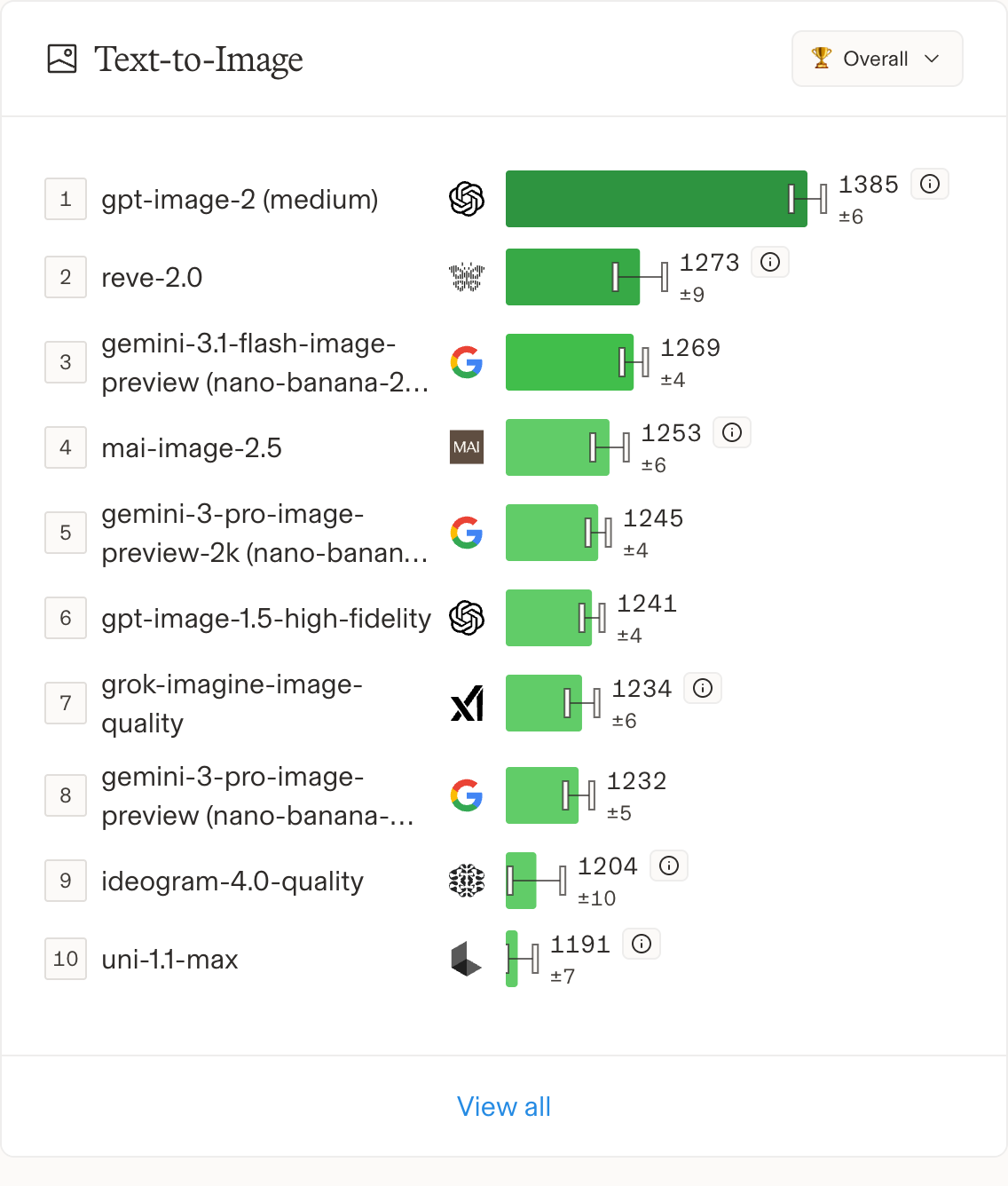
ChatGPT や Codex から画像生成しても良いのですけどね。ブラウザ開いたりダウンロードしたりは面倒だし、プロンプト考えるのも意外に大変だし、Claude Codeに「プロンプトを考えてください。こっちで画像生成AIにコピペして画像作らせるから」というのもスマートじゃない。
Claude Code との対話が分断されることなく、プロジェクト内のファイルを参照させたり、会話のコンテキストも考慮して貰いながら画像生成できたほうが良いよね、ってことでスキル化した次第です。
第一弾の ccskill-nanobanana と同様に、OpenAI公式のプロンプトベストプラクティスを内蔵しました。あと手元で色々と試して得たノウハウも組み込んでます。このへんがスキル化の良さで、MCPでは難しいとこですね。
(公式のプロンプトガイド。その情報をスキルに組み込んでいる)
画像生成が必要なシーンで、プロンプトに苦心する必要がなくなります😊
ccskill-gptimage を使った作例
いくつか作例をご紹介したいと思います。リポジトリにも色々と作例があるのですが、このブログの投稿用に改めて生成してみました。
日本語のテキスト描画が強いのは評判通りだなと思います。特に縦書きが良い感じに出てくるなーと。

(日本語の漢字・かなが崩れにくい。文字入りのビジュアルをそのまま使える水準に)
Web システムのモックやワイヤーフレームも得意な印象。システム開発で顧客要件を食わせてモックを描かせてから確認し、問題なければ Claude Code に「この画像の通りに実装して」みたいな使い方もできます。
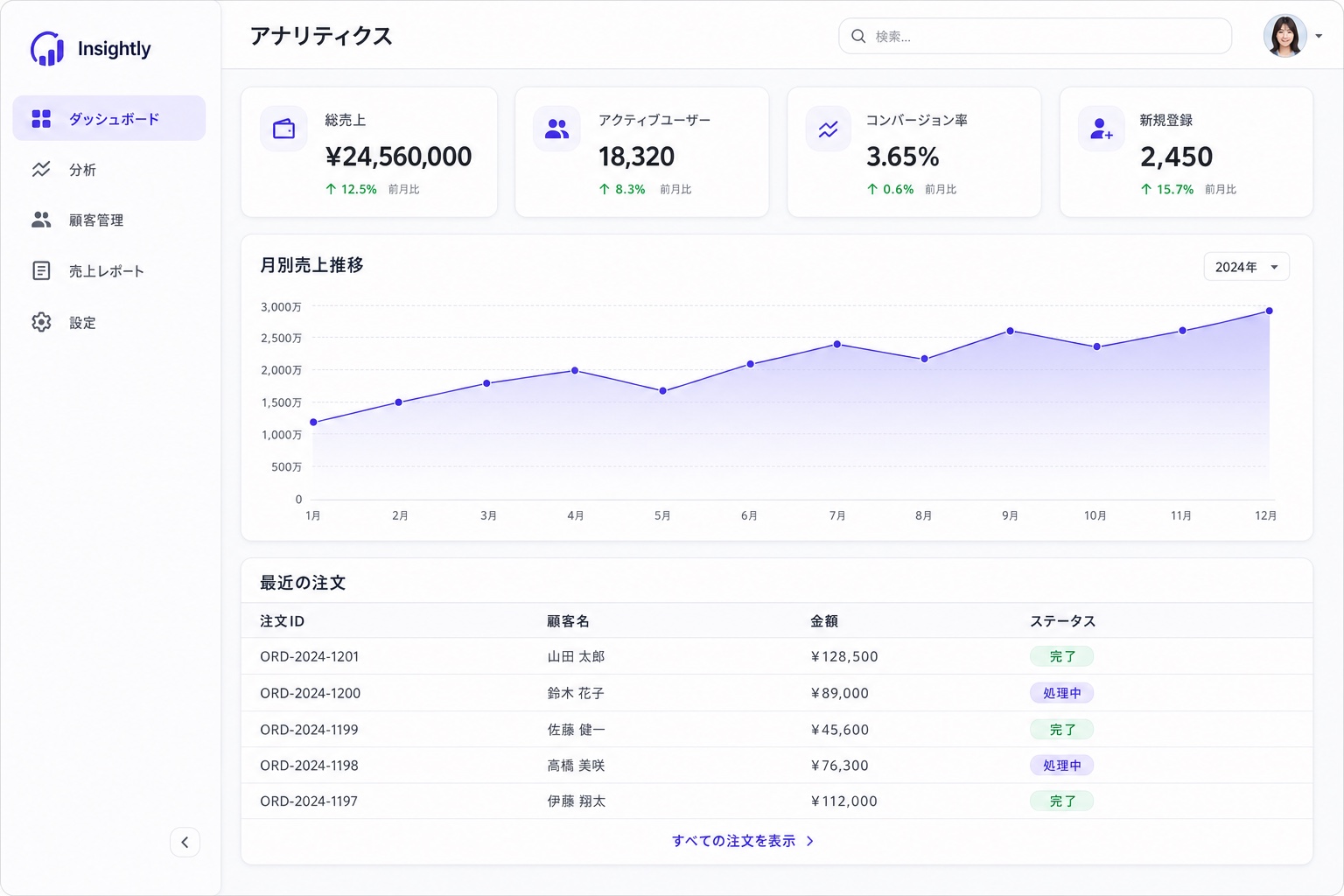
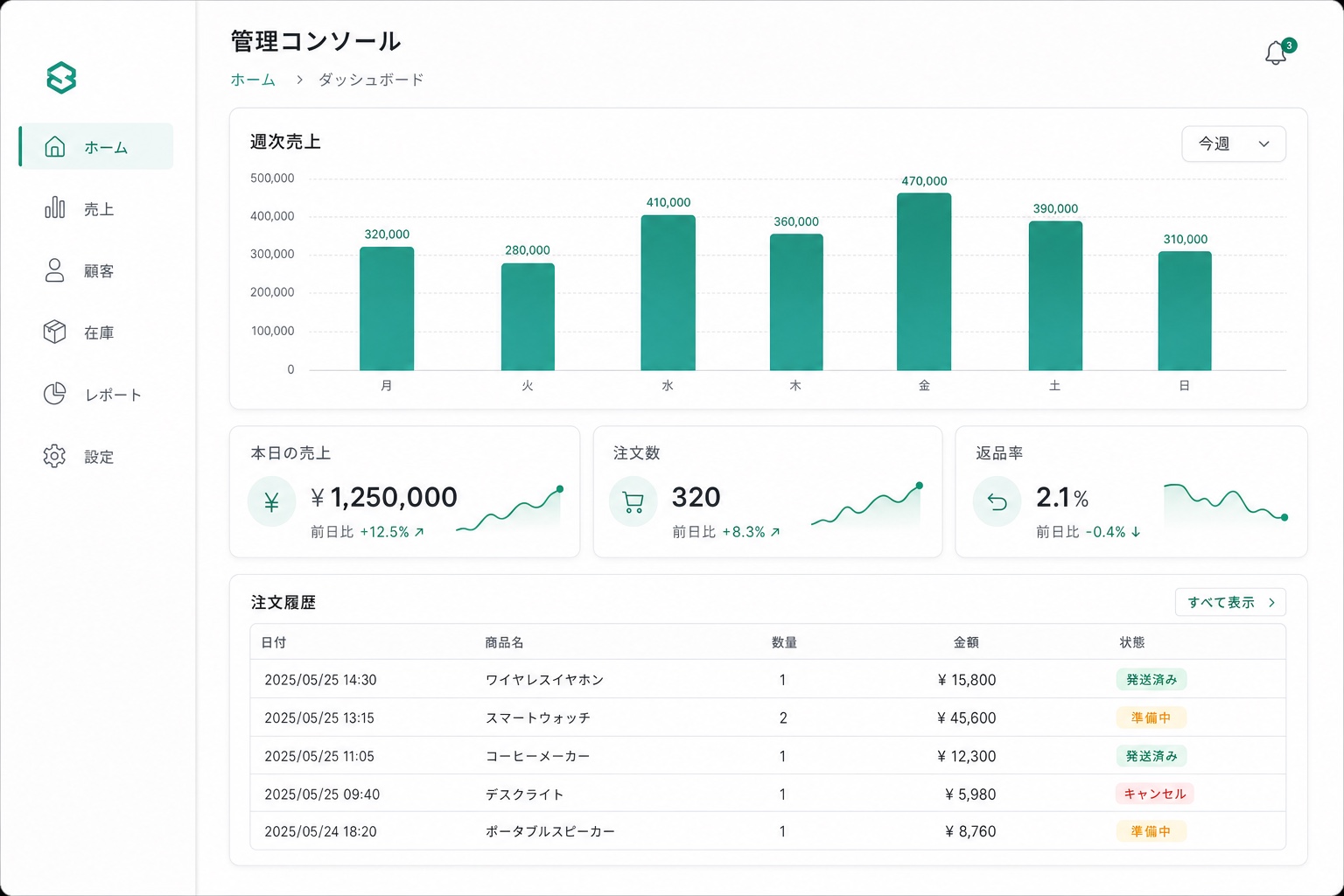
(あるWebシステムの画面モックを2パターン。日本語ラベルもしっかり破綻なく出るのは嬉しい)
写真系も悪くないと思います。看板やメニューみたいな文字も、漢字/ひらがな/縦書きが混在してても結構頑張ってくれる印象です。

(写真の中の日本語も破綻しにくい)
説明的な図もすんなり出力してくれるので、プレゼン資料を作成しているような場合は効率がUPしそうです。
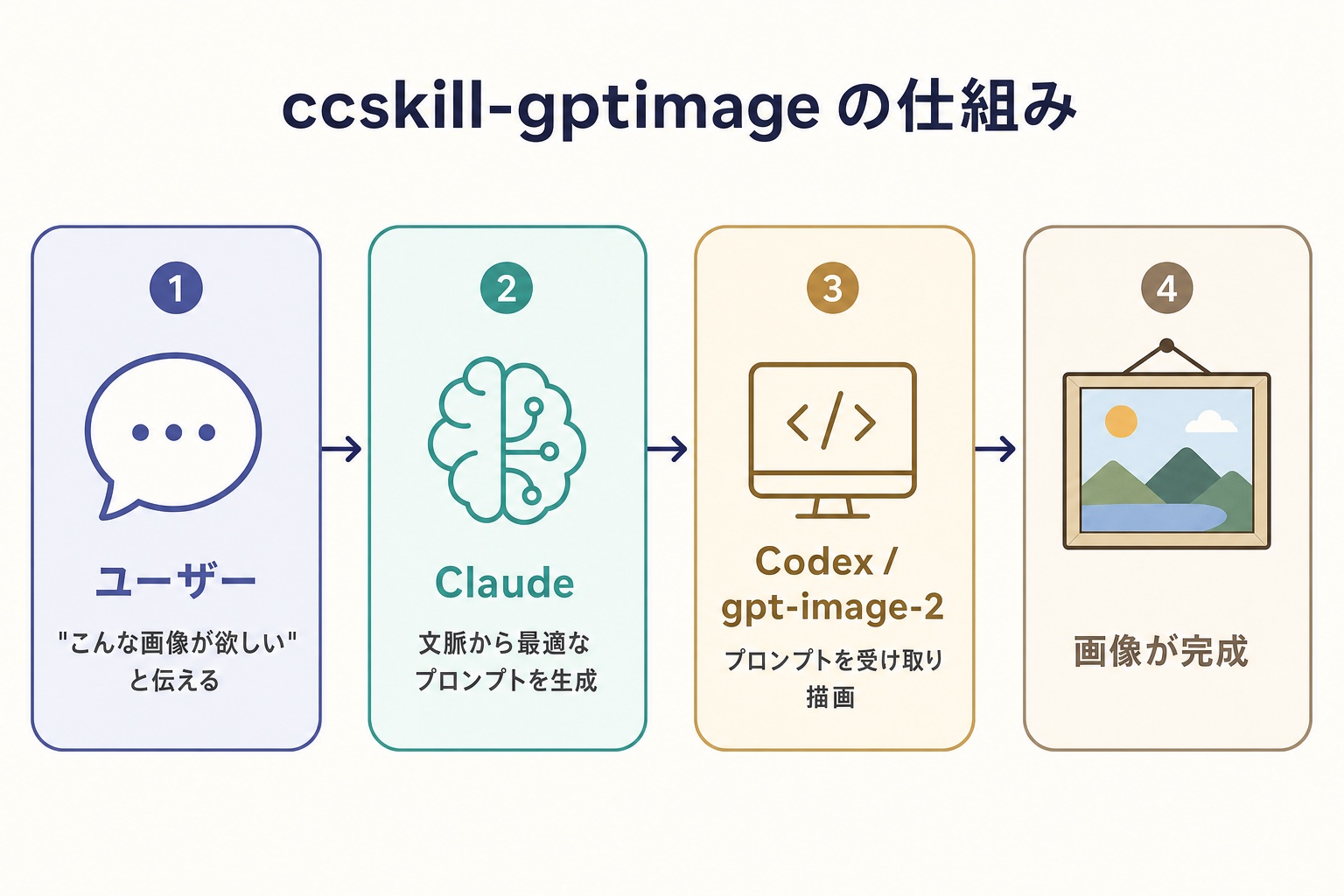
生成して貰ったあとに、「いいっすね!ついでにマージンを確保してトリムしてー」とか Claude Code に伝えて、続きで画像加工も依頼できたりします。作業が分断しないの大事。
他にも抽象画みたいなものや、

ロゴマークとかもざっくり指示で生成してくれますし、
![]()
(文字なしのシンボルロゴ。アプリアイコンの叩き台にも)
生成した画像を元に「後ろから見たバージョンも作って」ってな感じで、編集・加工、別パターンの生成をお願いすることも可能です。
![]()
(後ろ姿なので厳密には左右の色は反対であるべきだけどw さらに「青とオレンジ逆にして」と言うと生成してくれる筈)
ちなみに、GPT Image2.0 は透過PNG画像には対応していないのですが、ccskill-gptimage では自動的に 1.5 に切り替えて透過PNGも生成できるようにしています。
最後に興味深い(?)実験例を。
ここまでに載せた作例画像を全部渡して「これまでの画像を全部1枚の画像に詰め込んで」と無茶振りした結果が以下です。
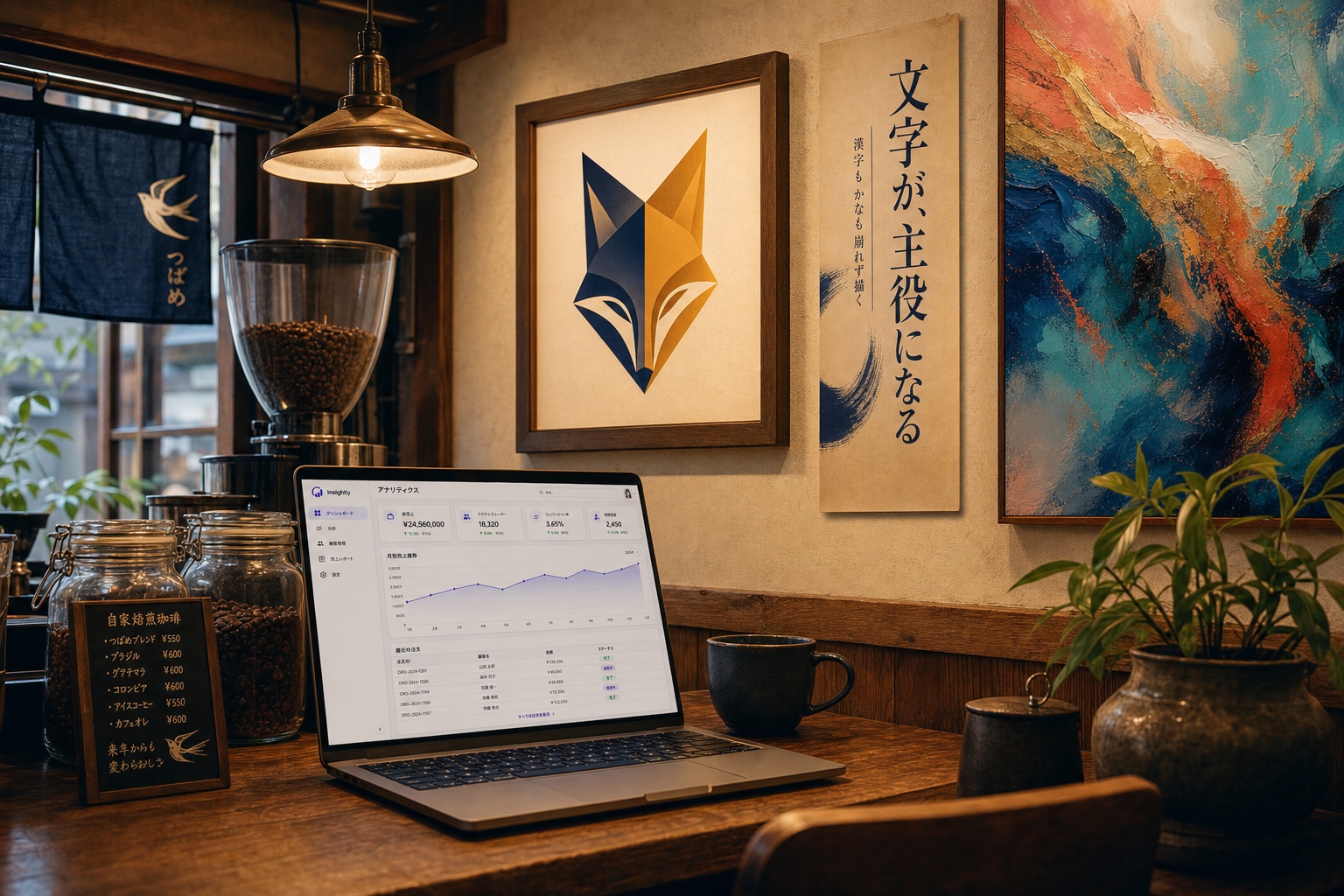
画像の合成力もなかなかのものですね。和風カフェ内でMacで作業中というまさかのシーン描写。GPT Image2.0 の画像解釈力と意味を繋げる理解力、創造力を表してる気がしました。一部抜けてる画像もありますが。
ってことで色んな作例を並べてみましたが、こうした画像生成をブラウザを開かずにClaude Code との対話の中で自然に行えるのが良いです。他にも、サブエージェント使って並行で走らせるとか、Agent Teams を使ってエージェント間でレビューし合って自律的に画像を改善させるとか、Claude Code の仕組みに画像生成を組み込めるのも便利だなと感じます。
APIキーを使わずに画像生成できる
GPT Image2.0 は、課金前提のAPI経由だけでなく、ChatGPTのProプラン以上でログインしてるCodexがあれば、追加料金不要で画像生成できるのが面白いところです。
そこで、ccskill-gptimage では、Codex 経由とAPI経由の2種類の使い方を用意しています。デフォルトは前者。明示的に指定することもできますし、自動的に判断させることもできます。
| Codex 経由 | API 経由 | |
|---|---|---|
| 必要なもの | ChatGPT サブスク(Plus以上) + Codex CLI ログイン | OpenAI APIキー + Organization Verification |
| APIキー | 不要 | 必要 |
| 手軽さ | ◎ ログインだけ | ○ 準備がやや要る |
| サイズ指定 | 非保証(非決定的) | 厳密に指定可 |
| 解像度 | 標準 | 最大4K(最大辺3840px) |
| 再現性・安定性 | ぼちぼち | 高い |
Codex 経由はサイズ指定に厳密性がかけるとか、理論上は4Kまでいけるのに生成してくれないとか、APIに比べて生成にちょっと時間がかかるとか色々気になるところはあるのですが、サブスクリプション契約をしていれば画像生成し放題というのは良いですよね。(rate limit でもちろん止められますが)
使い方としては、Codex経由でバックグラウンドでざっくり幾つか作ってみて、良さげなものを同じプロンプトでAPI経由で高品質に作り直し…みたいな使い方がベストかも知れません。そんな使い方も想定して、Claude Code が組み立てたプロンプトをJSONファイルに出力する仕様になっています。
たとえば、こんな3Dイラストをざっくり描かせたあと、

(アイソメトリックな3Dイラストも指示一発。窓の外の夜景や机上のコードまで作り込んでくれる)
画像と一緒に、以下のような JSON ファイルが残りますので、このプロンプトを再利用して API 経由の高品質版を作るとか。
{
"model": "gpt-image-2",
"prompt": "A polished isometric 3D illustration (intended use: clean blog visual). Scene: a cozy software engineer's home-office corner rendered in precise isometric projection on a soft neutral light background, room shown as a two-wall cutaway. Subject: a wooden desk with a glowing monitor displaying colorful code, a mechanical keyboard, a steaming coffee mug, a small potted monstera plant, a wooden bookshelf with neatly arranged books, a desk lamp casting warm light, a soft rug on light-wood flooring, and a window revealing cool blue evening city lights. Key details: smooth matte 3D materials, gentle ambient occlusion, soft warm interior lighting contrasting the cool dusk outside, rounded edges, tidy low-poly aesthetic, crisp high detail, balanced centered composition. Constraints: no text, no watermark, no logos, no people.",
"size": "1024x1024",
"quality": "high",
"background": "auto",
"output_format": "png",
"moderation": "auto",
"reference_images": [],
"mask": null,
"input_fidelity": null,
"revised_prompt": null,
"backend": "api",
"timestamp": "2026-06-18T22:08:08.089365"
}自分はあまりしませんが、他の画像生成AIにコピペするみたいな使い方もできます。
インストールと使い方
リポジトリのREADMEに書いている通りなのですが、git コマンドで clone して、インストール用のスクリプトを実行するだけです。
$ cd /path/to/projects/
$ git clone https://github.com/feedtailor/ccskill-gptimage.git
$ cd ccskill-gptimage && ./install.shPython 3.10 以上が必要です。スクリプトが自動的に venv を使って仮想環境作ったり、ライブラリをインストールしたりとかを行います。不安な方は Claude Code に「このスキル大丈夫か?」と聞いてみて下さい。
以前の ccskill-nanobanana では、各プロジェクトでシンボリックリンクを貼る…みたいな面倒な作業が必要だったんですが、今回は、~/.local/bin に専用コマンドを配備し、~/.claude/skills にユーザレベルでスキルを登録。インストール後はどのプロジェクトからでもいつでも使えるようにしました。
あとは、Claude Code との会話の中で「じゃぁ今までの議論を踏まえて製品画像を3パターン作って」ってな感じでざっくり頼めるようになります。細かなプロンプトテクニックは不要です。
また、ちょっと応用ですが ~/.local/bin に専用コマンド ccskill-gptimage を配置しますので、
$ ccskill-gptimage generate "夕焼けの海岸線" --size 1024x1536 --quality highのようにターミナルから画像生成したり、このコマンドを使う前提で何か定型的な処理を行うスクリプトを Claude Code に開発させる…なんて使い方もできます。
ccskill-gptimage は GPT Image 2.0 が用意しているAPIは全部ではないものの大半を網羅していて、 --reference で参照画像を渡して既存画像を微調整(作例の部分で紹介した例)することもできたりします。
色んなオプションが使えるので詳しくは ccskill-gptimage generate --help を見るか、Claude Code に聞いてみて下さい。オプションを活用した作例も専用ページに掲載しています。
機能追加のリクエストや不具合のご報告など、お気軽にご連絡ください。
ccskill シリーズでは今後もスキルを続々と増やしていきます
ccskill シリーズは、nanobanana(画像生成)、gmail(Gメール)に続き、今回で第三弾になります。既に第四/五/六弾ぐらいまで開発中なので、順次公開していこうと思います。公式サイトもあります。
また、X(Twitter)のアカウント @ccskillx もありますので、よければフォローして下さいませ。
というわけで、画像生成スキルccskill-gptimage 公開のお知らせでした。最近は、非エンジニアな経営者さん向けに Claude Code 使いこなしのためのレクチャーをやってます。関心がもの凄く高いなーと感じますね。興味おありの方はご連絡ください。黒い画面が苦手でもセルフ開発ができるようになります。